
第一时间掌握

具有高信噪比的荧光成像已成为生物现象精确可视化和分析的基础。然而,不可避免的噪声对成像灵敏度提出了巨大的挑战。
清华大学的研究团队提供了空间冗余去噪 Transformer(SRDTrans),以自监督的方式去除荧光图像中的噪声。
该团队提出了基于空间冗余的采样策略来提取相邻的正交训练对,消除了对高成像速度的依赖。然后,他们设计了一种轻量级时空 Transformer 架构,以较低的计算成本捕获远程依赖性和高分辨率特征。
SRDTrans 可以恢复高频信息,而不会产生过度平滑的结构和扭曲的荧光痕迹。并且,SRDTrans 不包含任何关于成像过程和样本的假设,因此可以轻松扩展到各种成像模式和生物应用。
该研究以「Spatial redundancy transformer for self-supervised fluorescence image denoising」为题,于 2023 年 12 月 11 日发布在《Nature Computational Science》。

活体成像技术的快速发展使研究人员能够在微米甚至纳米尺度上观察生物结构和活动。荧光显微镜作为一种非常流行的成像方法,由于其高时空分辨率和分子特异性,有助于发现一系列新的生理和病理机制。荧光显微镜的根本目标是获得干净、清晰的图像,其中包含足够的样品信息,可以保证下游分析的准确性并支持令人信服的结论。
然而,受多种生物物理和生化因素的限制(例如,标记浓度、荧光团亮度、光毒性、光漂白等),荧光成像是在光子受限的条件下进行的,固有的光子散粒噪声严重降低了图像信噪比(SNR),特别是在低照度和高速观察时。
已经提出了各种方法来去除荧光图像中的噪声。基于数值滤波和数学优化的传统去噪算法性能不理想且适用性有限。过去几年,深度学习在图像去噪方面表现出了令人瞩目的表现。
在使用真实值 (GT) 数据集进行迭代训练后,深度神经网络可以学习噪声图像与其干净对应图像之间的映射。这种监督方式在很大程度上依赖于配对的 GT 图像。
在观察生物体的活动时,获得逐像素配准的干净图像是一个巨大的挑战,因为样本经常经历快速的动态变化。为了缓解这一矛盾,人们提出了一些自监督方法,从而在荧光成像中实现更适用和实用的去噪。
为了获得更好的去噪性能,同时提取全局空间信息和长程时间相关性的能力至关重要,而由于卷积核的局部性,这是卷积神经网络(CNN)所缺乏的。此外,固有的谱偏差使得 CNN 倾向于优先拟合低频特征,而忽略高频特征,不可避免地产生过度平滑的去噪结果。
清华大学的研究团队提出了空间冗余去噪 Transformer(the spatial redundancy denoising transformer,SRDTrans)来解决这些困境。
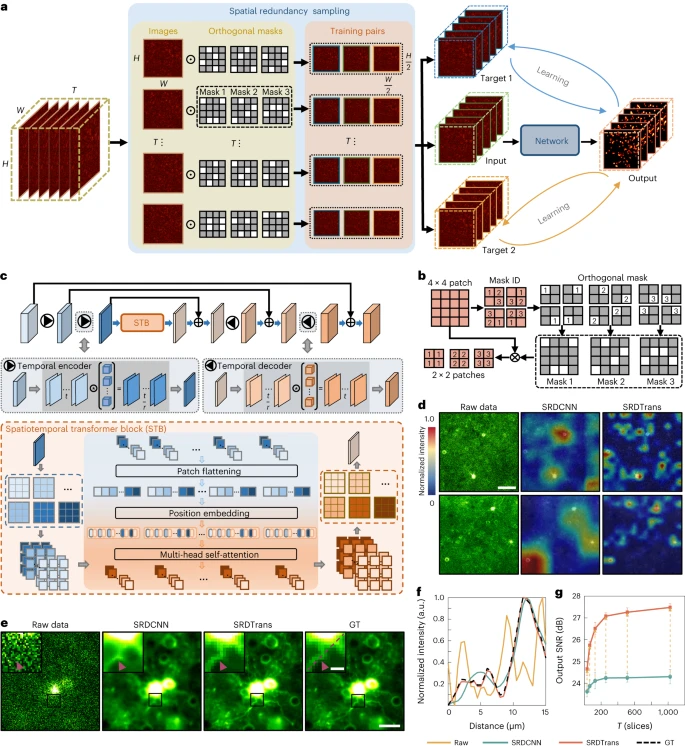 图:SRDTrans原理及性能评估。(来源:论文)
图:SRDTrans原理及性能评估。(来源:论文)一方面,研究人员提出了一种空间冗余采样策略,从两个正交方向的原始延时数据中提取三维(3D)训练对。
该方案不依赖于两个相邻帧之间的相似性,因此 SRDTrans 适用于非常快的活动和极低的成像速度,这与该团队之前提出的利用时间冗余的 DeepCAD 是互补的。
由于 SRDTrans 不依赖于任何有关对比度机制、噪声模型、样本动态和成像速度的假设。因此,它可以很容易地扩展到其他生物样品和成像方式,例如膜电压成像、单蛋白检测、光片显微镜、共焦显微镜、光场显微镜和超分辨率显微镜。
另一方面,研究人员设计了一个轻量级时空变换网络来充分利用远程相关性。优化的特征交互机制使该模型能够用少量的参数获得高分辨率的特征。与经典 CNN 相比,所提出的 SRDTrans 具有更强的全局感知和高频维护能力,能够揭示以前难以辨别的细粒度时空模式。
该团队在两个代表性应用中展示了 SRDTrans 的卓越降噪性能。第一个是单分子定位显微镜(SMLM),相邻帧是荧光团的随机子集。
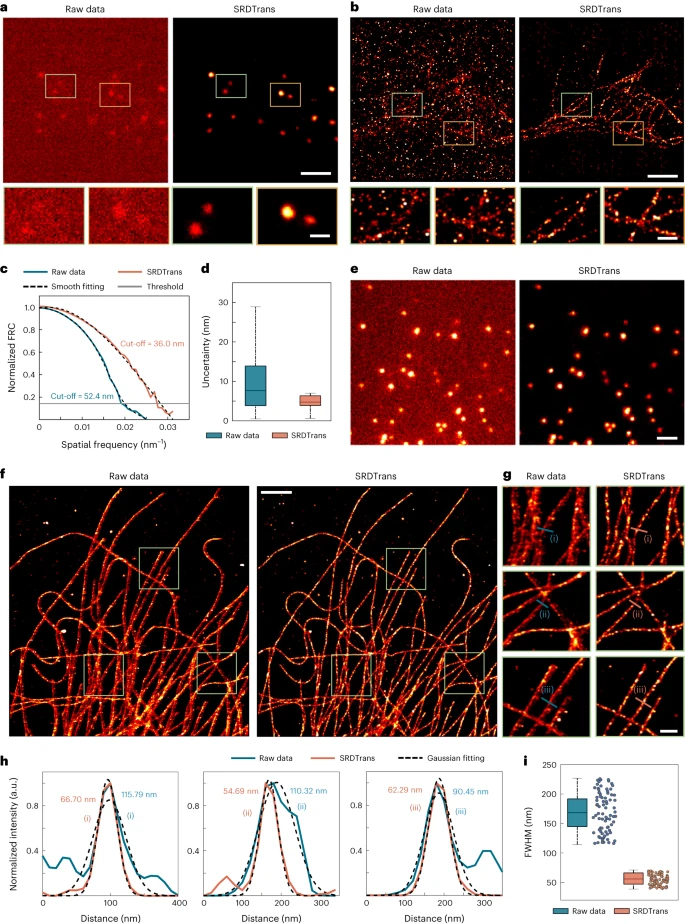 图:将 SRDTrans 应用于实验 SMLM 数据。(来源:论文)
图:将 SRDTrans 应用于实验 SMLM 数据。(来源:论文)另一种是大型 3D 神经元群的双光子钙成像,体积速度低至 0.3Hz。广泛的定性和定量结果表明,SRDTrans 可以作为荧光成像的基本去噪工具,从而观察各种细胞和亚细胞现象。
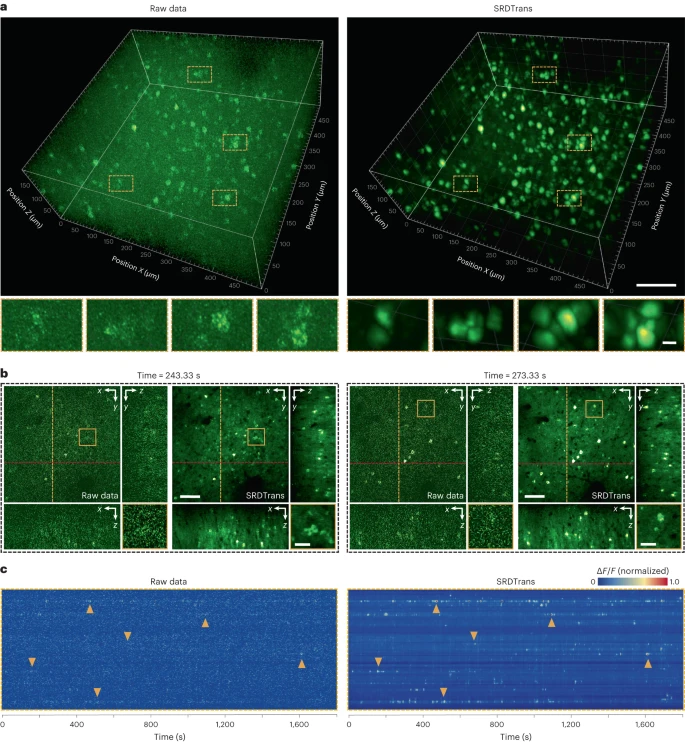 图:大神经体积的高灵敏度钙成像。(来源:论文)
图:大神经体积的高灵敏度钙成像。(来源:论文)SRDTrans 也有一些局限性,主要在于相邻像素应具有近似结构的基本假设。如果空间采样率太低而无法提供足够的冗余,SRDTrans 将失败。另一个潜在的风险是泛化能力,SRDTrans 的轻量级网络架构更适合特定任务。
相信针对特定数据训练特定模型是使用深度学习进行荧光图像去噪的最可靠方法。因此,应该训练新的模型,从而确保在成像参数、模态和样本发生变化时获得最佳结果。
随着荧光指示剂的发展朝着更快的动力学方向发展,以监测毫秒级的生物动力学来记录这些快速活动所需的成像速度不断增长。对于依赖时间冗余的去噪方法来说,获得足够的采样率变得越来越具有挑战性。该团队的观点是通过寻求利用空间冗余作为替代方案来填补这一空白,从而在更多成像应用中实现自我监督去噪。
尽管空间冗余采样的完美情况是空间采样率比衍射极限的奈奎斯特采样高两倍,从而确保两个相邻像素具有几乎相同的光学信号;但在大多数情况下,两个空间下采样的子序列之间的内生相似性足以指导网络的训练。
然而,这并不意味着所提出的空间冗余采样策略可以完全取代时间冗余采样,因为消融研究表明,如果配备相同的网络架构,时间冗余采样可以在高速成像中取得更好的性能。SRDTrans 在高成像速度下相对于 DeepCAD 的优势实际上归功于 Transformer 架构。
一般来说,空间冗余和时间冗余是两种互补的采样策略,可实现荧光延时成像去噪网络的自监督训练。使用哪种采样策略取决于数据中哪种冗余更充分。值得注意的是,在许多情况下,两种冗余都不足以支持当前的采样策略。开发特定的或者更通用的自监督去噪方法,对于荧光成像具有持久的价值。
论文链接:https://www.nature.com/articles/s43588-023-00568-2
清华大学生物训练显微镜

 新浪科技公众号
新浪科技公众号 “掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)
 相关新闻
相关新闻 
